The PlanetScale CEO Said I Don't Value My Time. Here's My $22/Month Server Running 4 Apps.

Yesterday I posted something on X that got the CEO of PlanetScale in my replies.
I said that a red flag for me with a young African startup is when I see Supabase, Neon, PlanetScale, or any auth-as-a-service on their stack. That it tells me you’re building from hype, not from math.
Sam Lambert, CEO of PlanetScale, replied:
This is a bad take. Not using external services shows you don’t value your time or understand how much work you need to do on the differentiated parts of your product.
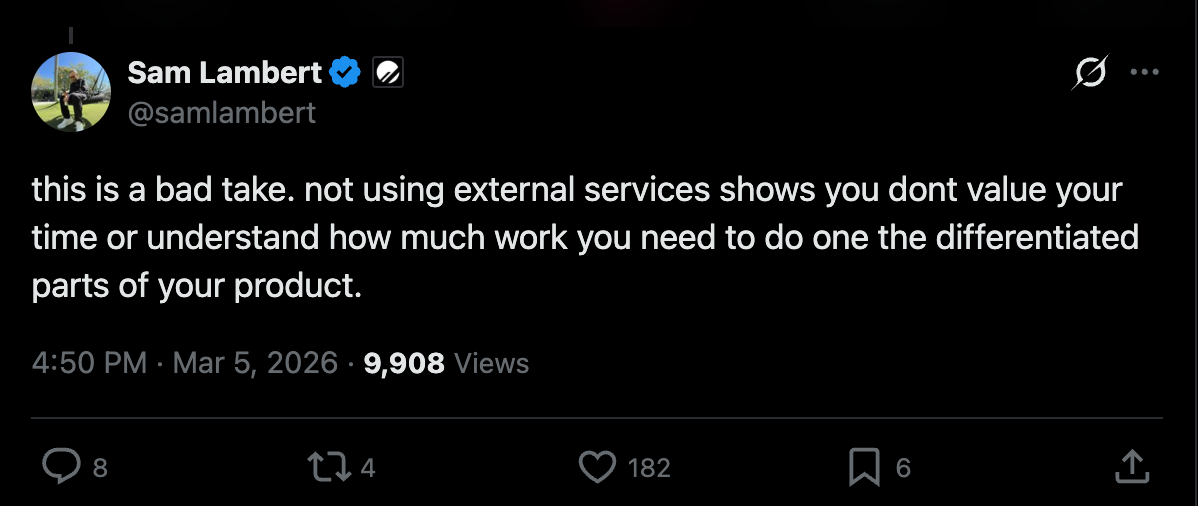
He followed up with the following:
This would not happen on the majority of the services you are talking about. I think this thread reveals that you don’t understand how database systems operate and that makes your advice pretty dangerous.
So not only do I not value my time. I also don’t understand databases, and my advice is “pretty dangerous.” We’ll come back to that.
Another commenter said:
Nobody who has operated infrastructure themselves has ever described it as painless.
On LinkedIn, a senior engineer wrote:
Using Auth-as-a-Service doesn’t necessarily mean a startup copied it from a YouTube tutorial. Authentication involves security, password management, MFA, account recovery, and ongoing maintenance.
And another:
If you’re testing an idea, most of these are often free for a small scale project. Only when things start to become serious should you migrate.
These are smart people making reasonable points. I disagree with the conclusion, but I understand the logic.
Here’s mine.
Cost-effectiveness is part of your job
Let me start with something that shouldn’t be controversial but apparently is: knowing what your stack costs and whether that cost is justified is a core engineering skill. It’s not a finance problem. It’s not an ops problem. It’s your problem.
This isn’t just me talking. Werner Vogels, the CTO of AWS (the company that literally makes more money when you spend more on cloud), dedicated his 2023 re:Invent keynote to what he called “The Frugal Architect.” Go watch the keynote. His argument: cost is a non-functional requirement, just like performance and security. Organizations need to consider cost and sustainability from the start, not as an afterthought.
If the CTO of AWS is telling you to be frugal, and you’re racking up $105/month in managed services for an app with 40 users, someone isn’t listening.
David Heinemeier Hansson (creator of Ruby on Rails, co-founder of 37signals) left the cloud entirely. Their AWS bill was $3.2 million per year. They bought $700,000 in hardware, and their savings will top $10 million over five years. Same team size. No additional hires. Same products. He called cloud vendors “merchants of complexity”.
Pieter Levels runs NomadList, RemoteOK, and PhotoAI. $3 million per year in revenue with zero employees. His infrastructure costs? Less than $200/month. Plain PHP on a single VPS. No Kubernetes. No Supabase. No auth-as-a-service. He once said the priority is “getting customers and getting people to pay money, because then you survive.”
According to CloudZero’s 2024 State of Cloud Cost report, 91% of engineering teams now have some level of ownership over cloud costs. 44% say engineering always takes responsibility for it. And two-thirds report that investigating rising cloud costs disrupts their workflows. Equivalent to a full sprint for 22% of them.
Gartner estimates that 60% of cloud spending will be wasted in 2025. For a startup burning $50,000/month on infrastructure, that’s $30,000 going nowhere. And 29% of startups fail due to running out of cash. The second most common reason for failure.
This is the landscape Sam Lambert’s advice lives in. “Focus on differentiated work” sounds right. But if your undifferentiated infrastructure costs are eating your runway, you won’t survive long enough to differentiate anything.
And to the commenter who asked “would you rather have a shorter runway and work on your actual product, or a longer runway and spend all of your time messing with your database?” I’d rather have a longer runway AND work on my product. That’s not a hypothetical. That’s my Tuesday.
Your job as an engineer at a startup is problem solving. Cost-effectiveness is one of those problems. It’s not a distraction from the real work. It IS the real work. Building cost-effectively is an engineering challenge, and solving it well buys you the time to solve everything else.
Stop burning through other people’s money (free credits, grants, startup fundraises) on infrastructure you could run yourself for pennies. Those resources should fund distribution, design, and user acquisition. Not Supabase Pro for 40 users.
The math nobody in my replies wanted to do
Here’s a real cost comparison I put together in The DID Problem:
The hype stack:
- Vercel Pro: $20/month
- Supabase Pro: $25/month
- Auth0 Essentials: $35/month
- Total: $80/month. And that’s just hosting, database, and login. No Redis, no file storage, no email.
The lean stack:
- Hetzner VPS: $6/month
- Slipway/Dokploy: free, self-hosted
- PostgreSQL: free, self-hosted
- Auth: free, built into your framework
- Total: $6/month. Same app. Same performance.
That’s a 92.5% cost reduction. Over a year, $888 saved. Over two years, $1,776. For a bootstrapped founder in Lagos or Nairobi or Accra, that’s months of runway. That’s distribution budget. That’s the things that actually kill startups.
The average Nigerian developer salary is about ₦339,000/month. Roughly $220. The hype stack costs nearly half that. For an app with 40 users.
Sam Lambert can afford to think in time because PlanetScale has raised over $100 million. When you have $100 million, $105/month is a rounding error. When you’re bootstrapping, it’s the difference between shipping for six more months and shutting down.
Someone on X put it perfectly: don’t only focus on what you can afford. Focus on what you can sustain. You might be able to afford $80/month today. But can you sustain it for 18 months with no revenue? That’s the question the hype stack never asks you.
Here’s the thing nobody talks about: constraint is a feature, not a bug. When you have $6/month for infrastructure instead of $80, you don’t build worse software. You build leaner software. You learn what PostgreSQL actually does instead of treating it as a black box behind an API. You understand your deployment pipeline instead of praying that Vercel’s magic works. You make architectural decisions based on what your system needs instead of what the marketing page promised.
The history of great engineering is the history of constraint. 640KB of memory gave us efficient algorithms. Slow networks gave us caching. Limited bandwidth gave us compression. Cost constraint gives you understanding. And understanding is the one thing you can’t buy from a managed service.
Sam Lambert said my advice is “pretty dangerous” because I “don’t understand how database systems operate.” But here’s the irony: I understand my database better BECAUSE I run it myself. I know my backup schedule, my retention policy, my restore process, my connection pool limits. I’ve tested my disaster recovery. Can every founder using PlanetScale’s managed database say the same? Or do they just trust that someone else has it handled?
The dangerous advice isn’t “learn to run your own infrastructure.” The dangerous advice is “don’t worry about it, just pay someone.” Because when that someone changes their pricing, deprecates their free tier, or has an outage at 2 AM, the founder who never learned is the one in danger.
And this isn’t even the worst case. A Vercel user received a $96,000 bill in a single month from serverless function usage after scaling to ~500K users without a spend limit. Another got a $46,485 bill for a static website in February 2026. 450 million page views at $0.15/GB after the included 1 TB on Pro. Someone literally wrote “I replaced a $200/month Vercel bill with a $5 VPS”. Usage-based pricing sounds friendly until your app gets popular. Then it gets terrifying. These aren’t isolated incidents either. Serverless Horrors has an entire collection of stories like these.
On a VPS? Your bill doesn’t change when your traffic spikes. It’s the same €5.49 whether you get 100 visitors or 100,000.
”But free tiers exist”
This was the most common reply. “Clerk is free for 10,000 users.” “Supabase is free until you hit the limits.” “One prototypes without much code commitments.”
And they’re right. For now.
PlanetScale had a free Hobby plan too. Until March 2024, when they deprecated it. Databases that weren’t upgraded to Scaler Pro by April 8th were put to sleep. You had to pay to wake them up. PlanetScale laid off staff at the same time.
Heroku did the same in November 2022 and removed all free tiers, forcing millions of hobby projects offline.
Supabase pauses free projects after 7 days of inactivity. Paused projects are restorable for only 90 days. After that? Users have reported table data lost after trying to restore from a paused state.
Neon was acquired by Databricks for ~$1 billion in May 2025. Users on Hacker News immediately started worrying about the platform’s future direction. Today’s free tier is tomorrow’s enterprise pivot.
The irony of Sam Lambert’s reply is that his company is the proof of what I’m warning about. PlanetScale offered a free tier. Founders built on it. Then PlanetScale changed the terms. Databases were slept. Data was held hostage behind a paywall.
Free tiers are customer acquisition funnels disguised as generosity. The “free” is temporary. The lock-in is permanent. You build your schema on their platform. Your connection strings point to their servers. Your migration path is whatever they allow. GridPanel wrote an entire blog post about losing trust in PlanetScale after their database went down without warning and support was limited to a 2-business-day response time. Unless they paid $1,000/month to upgrade.
When the free tier disappears (and it will, because these are VC-funded companies that need to show returns) you either pay up or scramble to migrate under pressure.
A self-hosted PostgreSQL on your own VPS doesn’t have a pricing page. It doesn’t have a free tier that expires. It doesn’t sleep your data. It’s just PostgreSQL. On your server. For as long as you want it.
Here’s a thought experiment: what if these services never had free tiers at all? If every managed database, every auth service, every serverless platform charged from day one, would founders still pick them? Or would they learn to run their own infrastructure, build with leaner tools, and focus on building things people actually want instead of racking up services they’ll eventually have to pay for or migrate away from? I think the free tier is doing more harm than good. It’s training a generation of builders to depend on services they don’t understand and can’t afford at scale.
Murphy’s Law comes for everyone
Let me be clear about something: I am not shaming anyone for using managed services. These are companies staffed with talented engineers building real technology. I’m not saying they’re bad at what they do.
I’m saying Murphy’s Law doesn’t care who runs your infrastructure.
Things go wrong. For everyone. I haven’t experienced a data loss incident yet (knock on wood) and I take that seriously. I’m not naive enough to think I’m immune. But what I want to point out is that the managed services people trust as their safety net? They’ve had their Murphy’s Law moments too. And when they do, you have zero control over the outcome.
Supabase
October 2025: Users discovered that restoring from a backup was corrupting entire projects. The one safety net you’re paying for (backups) broke the thing it was supposed to protect. Users with paying customers were locked out. Some waited over a week for support. The restore function stayed enabled despite the known corruption issue.
February 2026: A major outage left 4.92% of all customers (thousands of production apps) completely unreachable for nearly four hours. No database access. Nothing.
And it’s not just availability. In 2025, security researchers discovered that 170+ apps built with AI tools had exposed Supabase databases because Row Level Security wasn’t enabled by default (CVE-2025-48757). They demonstrated mass exploitation with simple curl commands. Your “managed” database was wide open.
Clerk
February 2025: An engineer ran a bad database query to deprecate a feature for 3,700 customers. The query had an error. 3,700 apps lost authentication. Users couldn’t log in. Not because of anything you did. Because of someone else’s mistake. The downtime triggered cascading retries that nearly overwhelmed their entire infrastructure.
By June 2025, they’d had three major disruptions in two months. In the last 90 days alone, Clerk had 7 incidents: 2 major outages and 5 minor ones.
This is the auth service people are paying $35/month for instead of writing a login page. When it goes down, every single app using it goes down simultaneously.
Auth0
205 outages since July 2022. Averaging 4.9 incidents per month. Another auth-as-a-service with a worse track record than a self-hosted login page that has literally zero external dependencies.
Railway
February 2026: Their automated abuse enforcement system incorrectly terminated legitimate deployments including PostgreSQL and MySQL databases by sending SIGTERM signals. 3% of all workloads killed. Not by an attacker. By their own safety system.
Render
753+ outages documented for Render PostgreSQL over nearly 6 years. Users have complained about incorrect status reporting making it impossible to even know when problems exist.
PlanetScale
October 2025: A near-total control plane outage from DNS misconfiguration meant customers couldn’t create or resize databases in us-east-1 for hours.
Heroku
April 2022: Attackers exfiltrated OAuth tokens and customer credentials. Heroku took over a month to fully disclose the breach. The company that an entire generation of developers trusted with “just push to Heroku.”
Vercel
October 2025: An AWS us-east-1 disruption cascaded through Vercel’s entire control plane: dashboard, APIs, builds, log processing. All down. August 2024: An upstream provider’s misconfiguration took down Edge Middleware and Edge Functions globally.
I’m not listing these to dunk on anyone. Every system has failure modes. Every company has bad days. I’m listing these because the promise that “managed means you don’t have to worry” is a lie. You still worry. You just can’t do anything about it when it happens.
When something goes wrong on my VPS, I fix it. Right now. Because I own it. When something goes wrong on Supabase’s end, you open a support ticket and wait.
”You should avoid hosting your own database if you really care about data”
This was a LinkedIn reply that hit a nerve. The suggestion that self-hosting is inherently reckless with data. That you need a managed service to keep your data safe.
I have never lost a single byte of production data. Not once. Not a corrupted row. Not a vanished table. Not a backup that failed to restore. Knock on wood.
And I’m not flying blind either. Here’s what my setup does. And this is a good time to talk about what Slipway actually gives you today, because a lot of the “self-hosting is painful” arguments come from people who haven’t looked.
What Slipway already gives you
Slipway is an open-source, self-hosted deployment platform I built specifically for Sails.js apps. I built it in a week. Its memory footprint is ~120MB. It runs on a Hetzner VPS that costs less than $22/month, deploys 4 apps, 4 PostgreSQL databases, and 4 Redis stores. Slipway does a lot more than most people realize.
Deployments that don’t break things
Zero-downtime deploys. When you run slipway slide, Slipway builds a new Docker image, starts a new container, runs HTTP health checks against it for up to 30 seconds, and only switches traffic via Caddy when the new container is confirmed healthy. If the health check fails, the old container keeps running. Nothing breaks. The industry term for this is a blue-green deployment.
One-click rollbacks. If something goes wrong, roll back in seconds from the dashboard. Navigate to a previous deployment and slide to rollback. It reuses the existing Docker image so there’s no rebuild. Instant.
Auto-deploy from GitHub. Push to your branch, Slipway deploys automatically via webhook. Configure branch-to-environment mapping: main goes to production, develop goes to staging. It even creates preview environments for pull requests. Isolated deployments that spin up when a PR opens and destroy themselves when it closes.
Deployment logs. Full visibility into what happened, when, and why.
Databases without the vendor lock-in
Four engines. PostgreSQL (13-16), MySQL (5.7, 8.0), Redis (6, 7), MongoDB (5-7). One command: slipway db:create. Connection strings auto-injected into your app’s environment variables. No manual configuration.
Automated backups to S3-compatible storage. Schedule backups to Cloudflare R2, AWS S3, or DigitalOcean Spaces. Compressed SQL dumps. Offsite. Configurable retention: time-based (e.g., 30 days) or count-based (e.g., last 10). One-click restore from S3 when you need it.
Dock: a database command center. Browse tables. Run SQL queries (with built-in safety that blocks destructive operations like DROP DATABASE). Inspect schema. And the standout feature: schema diff and one-click migrations. Dock compares your Waterline model definitions against the actual database schema and generates the SQL to synchronize them. Review it. Click apply. Done.
No external database GUI. No SSH. No pgAdmin. It’s all in the browser.
Monitoring that actually tells you things
Lookout is the observability dashboard. It tracks:
- HTTP requests: Method, URL, status code, duration, p95 latency
- Exceptions: Unhandled errors, promise rejections, stack traces
- Slow database queries: Any Waterline query exceeding your configured threshold (default 100ms)
- Cache operations: Hit/miss rates, writes, deletes, top keys
- Infrastructure: CPU, memory, network I/O, disk I/O, process counts. Per container, with 24-hour history
Lookout doesn’t just display data. It alerts. If CPU or memory stays above 90% for sustained periods, if a container stops unexpectedly? You get notified.
Notifications on everything that matters
Five channels: Discord, Slack, Telegram, email, and webhooks (for n8n, Zapier, Make, or your own endpoints).
Events that trigger alerts:
- Deployment succeeded or failed
- Backup completed or failed
- Container stopped unexpectedly
- High CPU or memory usage
- Background job failures
I get an email when anything goes wrong. No third-party monitoring service needed.
Production tools that replace expensive SaaS
Helm is a production REPL in the browser. Execute Sails helpers, run Waterline queries, inspect data, debug issues. No SSH. No tunneling. Just open the dashboard and run await User.find({ email: '[email protected]' }).
Bridge is an auto-generated admin panel. Slipway inspects your running app’s Sails models and generates a full CRUD interface. List views with sorting, search, and pagination. Create/edit forms matched to your model definitions. Relationship management. Bulk operations. Think Laravel Nova, but automatic and free.
Content is a visual CMS for apps using sails-content. Edit markdown, manage frontmatter, deploy changes. All from the dashboard.
Quest is a job scheduler dashboard. View all scheduled jobs, their status, their schedule. Run now. Pause. Resume. Monitor failures. All in the browser.
Bosun is the self-administration dashboard for the Slipway instance itself. System overview, process metrics, environment variable management, a SQLite console for querying Slipway’s own databases, and a unified activity feed of deployments, backups, and audit logs.
Everything else
- Automatic HTTPS via Caddy with Let’s Encrypt. Custom domains with automatic SSL.
- File uploads to S3-compatible storage (persistent across deploys because container filesystems are ephemeral.
- Team management with four roles (Owner, Admin, Developer, Viewer), project-level permissions, audit logs, and SSO support.
- Deploy tokens for CI/CD pipelines. Environment variables per-app and global. Secrets management.
All of this. On one VPS. Under $22/month. ~120MB of memory.
That’s not painful. That’s a better developer experience than most managed service dashboards. And I own every byte of it.
Writing this post also taught me a couple of things about where Slipway falls short. I’ve already started addressing those gaps. If you’re going to advocate for a tool, you should be honest about its edges too.
Slipway isn’t perfect. No software is. It’s not even at 1.0 yet. But it runs all my apps in production: hagfish.app, temboai.com, sailscasts.com, africanengineer.com. That’s the bar that matters.
”Nobody calls self-hosting painless”
It was true in 2018. It’s not true in 2026.
I moved from Render (managed, expensive, limited) to Coolify (self-hosted but bloated and generic) to Slipway (self-hosted, purpose-built, lightweight). Each migration took less time than the last.
AI dropped the barrier to all of this to the floor.
You don’t need to memorize PostgreSQL configuration. You don’t need to write Dockerfiles from memory. You need to understand what you want (automated backups, monitoring, zero-downtime deploys) and let AI help you set it up. That’s what I did.
I’ll be honest: I never seriously worked with Docker before AI made it approachable. Now I appreciate the technology deeply. Here’s the thing most developers don’t realize: container tech is what powers most of these X-as-a-service platforms you’re paying for. Render, Railway, Fly.io, Heroku.
They’re all running your code in containers. The only difference is who manages them and how much you pay for that management. If you care about being cost-effective, learning how containers work isn’t optional. It’s leverage.
It doesn’t cost much to care anymore. The knowledge gap that used to make self-hosting intimidating? AI closed it. The tooling gap that made it tedious? Platforms like Slipway, Dokploy, and Coolify closed it. The only gap left is agency. The willingness to own your infrastructure the way you own your product.
One LinkedIn commenter put it perfectly: “Ignorance is expensive. And the price will only get higher with the vibe coders now coming into the picture.”
Racking up SaaS bills is not a flex. It’s a liability. Every service you don’t understand is a single point of failure you can’t debug. Every managed dependency is a company whose business decisions can break yours.
The real risk isn’t technical. It’s dependency.
Every managed service you adopt is a decision you’ll have to unmake later. And unmaking decisions is always harder than making them.
Your auth is on Clerk? Now your user table, your session logic, your middleware. All of it depends on Clerk’s API being up, their pricing staying reasonable, and their company surviving. When Clerk goes down, 3,700 apps lose authentication simultaneously.
Your database is on Supabase? Now your data lives on someone else’s servers, backed up by someone else’s restore process that might corrupt your project if you use it.
Your hosting is on Vercel? One good month of traffic and you might be staring at a $96,000 invoice.
When I self-host, my PostgreSQL is just PostgreSQL. My backups are PostgreSQL custom .dmp files I can restore anywhere. My containers are Docker containers I can run on any Linux server. If Hetzner disappeared tomorrow, I’d move to another VPS and be back online in minutes. Nothing proprietary. Nothing locked in.
The commenter who said “only when things start to become serious should you migrate” has it backwards. When things are serious is the worst time to migrate. You have users. You have data. You have uptime expectations. The best time to own your infrastructure is before you need to.
What I’m actually saying
I’m not saying managed services are evil. I’m not saying self-host everything.
I’m saying don’t do it mindlessly.
If you’ve done the math and Supabase’s free tier makes sense for your validation phase, use it. If Clerk’s 10,000-user free tier gets you to product-market fit faster, fine. If Neon’s serverless PostgreSQL lets you ship a prototype this week instead of next month, ship it.
But know the cost. Know the lock-in. Know the exit plan. Know that the “free” part is temporary. And know that when Railway’s abuse system kills your database, or Supabase’s backup restore corrupts your project, or PlanetScale sleeps your data behind a paywall? You’re at their mercy.
The commenter who said auth “involves security, password management, MFA, account recovery, and ongoing maintenance”? Yes, it does. And The Boring JavaScript Stack gives you session-based auth, magic links, passkeys, two-factor, and password reset out of the box. Most real full-stack frameworks have this built in. You don’t need a $35/month service for login.
To be clear: I’m not saying self-host everything. I would never self-host my own payment infrastructure. Billing involves PCI compliance, fraud detection, tax calculations, currency conversions, and regulatory requirements that change by country. That’s a domain where the managed service genuinely earns its fee. But don’t pretend that “Login with Google” is the same level of complexity as processing credit cards across 40 countries. Auth and payments are not in the same category. One is a solved problem your framework handles. The other is a regulated industry.
As Awais put it on LinkedIn after migrating PostgreSQL from Prisma and Redis from Upstash to his own VPS: his Upstash alone had already consumed 218,000 operations on a product he’d barely started.
Ship lean
The PlanetScale CEO thinks cost-awareness is a bad take. The AWS CTO built a whole framework around it. Pieter Levels runs a $3M business on $200/month of infrastructure. DHH saved $10 million by leaving the cloud.
I know who I’m listening to.
Stop building from hype. Start building from math. Stop treating your SaaS bill as a flex. It’s a tax on ignorance, and the DID problem will kill your startup long before a self-hosted PostgreSQL database ever could.
Not comfortable with your bill?
If you’re looking at your monthly infrastructure spend and feeling the weight of it. If you know you’re overpaying but aren’t sure how to move to a VPS without breaking things. I can help.
Ship Lean is a 45-minute consulting session where I review your stack, identify what’s costing you without adding value, and give you a concrete migration plan. What to cut. What to keep. What to self-host and how to do it without downtime.
You walk away with a plan you can execute in a week. Not vague advice. Specific steps.