I Tried to Build Africa's AI. The First Version Was Embarrassing.
“Àgbà kì í wà l’ójà, kí orí ọmọ títún wọ́.”
An elder does not stand in the market and let a child’s head go crooked.
I fed that proverb to my AI and asked it to explain the meaning. It responded in a language that looked like Yoruba but wasn’t. Correct diacritics. Correct tone marks. Full confidence.
But the words were hallucinated. Fabricated syllables strung together by a neural network that learned “African languages” from Reddit threads and Wikipedia dumps.

The AI’s name is Tembo. I built it. And that first version was embarrassingly wrong. Not just about this proverb, but about almost everything it tried to say in an African language.
The lie we all accepted
Every major AI model claims to “support” African languages. OpenAI lists Yoruba. Google lists Hausa. Meta lists Swahili. And technically, they’re not lying. If you ask ChatGPT to translate “Good morning” to Yoruba, it’ll give you something. If you ask Claude to speak Pidgin, it’ll try.
But here’s what nobody talks about: these models learned African languages the way a tourist learns “thank you” in five languages before a cruise. Surface-level pattern matching from parallel text corpora, not actual understanding.
Ask ChatGPT to have a natural conversation in Nigerian Pidgin and watch what happens. It’ll give you something like “I dey fine, how you dey?” and then immediately collapse into formal English.
Ask it to explain an Igbo concept like “chi” and you’ll get a Wikipedia summary, not the layered cultural understanding that any Igbo person carries intuitively.
The base models aren’t broken. They were never built for us in the first place.
So I decided to build my own
TemboAI started with a simple thesis: Africa needs an AI that speaks African languages natively. Not as translations, but as a natural part of how it thinks.
Named after the Swahili word for elephant (a symbol of wisdom, memory, and strength), Tembo was supposed to be different. An AI that understands tonal nuances, proverbial depth, code-switching between English and Yoruba mid-sentence. The rhythm of how Africans actually speak.
The vision was clear. The execution? That’s where things got humbling.
The first version was terrible
I’m not being modest. It was genuinely bad.
Here’s an actual conversation from the first fine-tuned model:
User: “Bawo ni, Tembo?”
Tembo: “Ẹ kú àárọ̀! Mo dúpẹ́ fún ìbéèrè rẹ. Bàwò ni ọjọ́ rẹ ṣe rí?” Grammatically plausible. Tonally correct. Except it completely ignored the question and responded with a generic greeting. Ask it anything in Yoruba and you got the same rehearsed pleasantries back. A parrot with diacritics.
User: “Wetin be the meaning of ‘wahala’?”
Tembo: Confidently explained that “wahala” means “a type of traditional celebration.” It doesn’t. Every Nigerian knows wahala means trouble, problems, stress. The model had encountered the word in training data but mapped it to the wrong semantic space entirely.
User: “Talk to me in Pidgin.”
Tembo: Produced something that read like a British person who watched one Nollywood movie and decided they could write a screenplay. Grammatically structured like English with random Nigerian words sprinkled in. No flow. No rhythm. No vibes.
The problem wasn’t the architecture. I was fine-tuning Qwen 3.5, a solid base model trained on trillions of tokens. The problem was the data.
The data problem nobody warns you about
When you fine-tune an LLM, you’re not teaching it from scratch. You’re adjusting its behavior with examples of how you want it to respond.
The base model already knows language structure, reasoning, and general knowledge. Your training data just steers it toward your specific domain.
The first batch of training data was 150,000 examples. Sounds impressive. It wasn’t.
When I audited it properly, I found:
- 68% were short translations. Pairs like “How are you?” / “Bawo ni?”, 50 to 100 characters long. These teach the model to be a dictionary, not a conversationalist.
- Hollow stub responses everywhere. “I can help you with that!” followed by nothing useful.
- Textbook-style formatting. Numbered lists, formal definitions, academic language. Nobody talks like that. Certainly no African elder I’ve ever met.
- Outright errors. Wrong translations, hallucinated word meanings, cultural information that was either outdated or just made up.
I had volume. I had zero quality.
The model learned exactly what I taught it: how to look like it speaks African languages without actually speaking them.
The audit that changed everything
I built an automated audit pipeline. Every single example was categorized:
- Keep: high-quality, culturally grounded, conversational
- Rewrite: good intent, bad execution (fix with a better LLM)
- Remove: too short, too wrong, or too generic to save
Out of 150,000 examples, roughly 12,000 survived the quality filter. The rest were either rewritten by a more capable model or thrown away entirely.
Then I started building new data from scratch. Not translations. Conversations.
A Yoruba proverb isn’t a one-liner you translate. It’s a story. It has context, a teaching moment, a way it’s used in daily life, a counter-proverb for when the situation is more nuanced.
So I built training examples that capture all of that. Multi-turn conversations where Tembo explains proverbs the way a wise uncle would, not the way a textbook would.
I rewrote Igbo dictionary entries into language teaching conversations with cultural context. I transformed BBC Pidgin news articles into natural discussions. I turned African folktales into griot-style storytelling conversations. Tembo isn’t a search engine. It’s a storyteller.
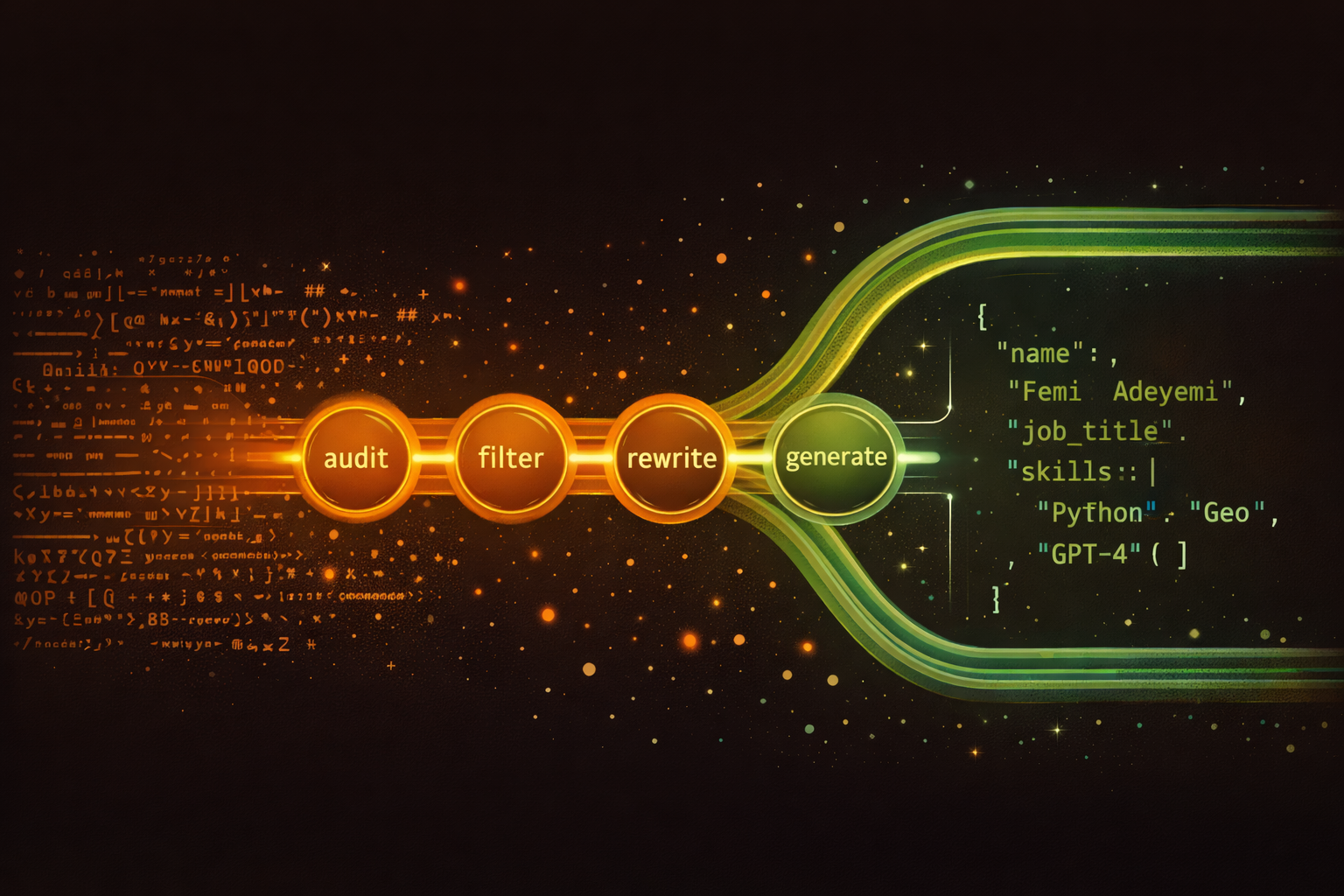
The pipeline: nine steps from raw data to training-ready JSONL
The whole system is a Python pipeline with nine generation steps. Here’s the flow:
- Audit — Rule-based scan of all 150K original examples. Categorize each as keep, rewrite, or remove. Result: 12K keepers, 105K flagged for rewrite, 18K trash.
- Filter — Clean the keepers. Upgrade the bare system prompt to the full Tembo personality prompt. Final quality pass.
- Rewrite proverbs — 500 Yoruba proverbs → 1,200 multi-turn conversations. Three variations each: wisdom-seeking, explanation, story-illustration.
- Rewrite dictionary — 8,500 Igbo dictionary entries → 2,500 teaching conversations with cultural context and pronunciation tips.
- Rewrite stories — 779 African folktales → 1,500 griot-style retellings with follow-up discussion.
- Rewrite transcripts — 77 real Naija Pidgin transcripts (gold-standard conversational data) → 300 user/Tembo conversations.
- Rewrite news — 2,500 BBC Pidgin and Masakhane articles → 1,800 casual topic discussions. Not summarization — real talk about the news.
- Rewrite task intents — 40K+ Injongo task intents across 25 African languages → 5,000 examples. Replace every hollow “Let me help you with that” stub with a real, culturally-aware answer.
- Generate conversations — Brand new multi-turn conversations across 10 categories: diaspora reconnection, Nollywood, food, language learning, mythology, business, daily life, history, education, creative writing. Target: 15,500 examples, 40%+ multi-turn.
Steps 3–9 are completely independent. Each one takes raw source material and an LLM, and produces a JSONL file. After all nine finish, a build step combines everything, deduplicates, balances the mix (no single source >30%), and splits into train/valid/test sets.
The critical insight: because the steps are independent, they can run on different LLMs simultaneously. And that changed everything.
The pipeline that ran for days
Here’s the part that tested my patience.
Every rewrite and generation step requires an LLM to produce the training example. I started with Ollama running Qwen 3.5 9B locally on a MacBook Pro with 64GB of unified memory. It works. It’s free. And it is painfully slow for 42,000 examples.
The pipeline has nine generation steps. Running them sequentially against a single local model, I was looking at roughly 34 hours of continuous generation. That’s almost a day and a half of your machine doing nothing but churning out training data, fans spinning, unable to do anything else.
For the first few steps (filtering originals, rewriting proverbs) that was fine. I’d start it before bed, check progress in the morning.
But as the remaining steps piled up (stories, dictionary rewrites, news discussions, code-switching examples, 15,500 new multi-turn conversations) the serial approach started feeling like carrying water from a river one bucket at a time when you need to fill a swimming pool.
The breakthrough: four cloud LLMs running in parallel
Then it hit me. These generation steps are independent. Rewriting stories doesn’t depend on rewriting news. Generating code-switching examples doesn’t need to wait for dictionary rewrites. They all just need an LLM and the raw source material.
So I split the workload across four cloud providers — three of them completely free:
Groq gives you 14,400 free requests per day with Llama 3.3 70B. I pointed the story rewriting script at Groq’s API. What took 4-5 seconds per story locally was taking 1-2 seconds on Groq. Quality was noticeably better because I jumped from a 9B model to a 70B model.
Google AI Studio gives you 1,500 free requests per day with Gemini 2.0 Flash. I aimed this at the news discussion generation.
Cerebras gives you 30 requests per minute and 1M tokens per day for free. I aimed this at the Injongo rewrites — 5,000 task intents that needed real, culturally-aware responses.
Together AI is the only paid provider. I pointed it at the conversation generation (15,500 multi-turn conversations across 10 categories) with Llama 3.3 70B Turbo at concurrency 10.
Four terminals. Four providers. Four progress bars.
The config change was trivial. The pipeline already used an OpenAI-compatible client. Adding providers was just swapping base URLs and API keys:
# Terminal 1
LLM_PROVIDER=groq python -m scripts.rewrite_dictionary # → Groq (free, Llama 3.3 70B)
# Terminal 2
LLM_PROVIDER=google python -m scripts.rewrite_news # → Google (free, Gemini 2.0 Flash)
# Terminal 3
LLM_PROVIDER=cerebras python -m scripts.rewrite_injongo # → Cerebras (free, GPT-OSS 120B)
# Terminal 4
LLM_PROVIDER=together python -m scripts.generate_conversations # → Together ($9.51)The free tier reality check
Here’s what I didn’t expect: the free providers mostly failed.
On paper, the math worked. Groq’s 14,400 requests per day should comfortably handle 2,000 dictionary rewrites. Google’s 1,500 per day should get through 2,200 news articles overnight. Cerebras’s 30 per minute should finish 3,125 Injongo rewrites in a few hours.
In practice, rate limits compound in ways the documentation doesn’t warn you about. My retry logic used exponential backoff (2 seconds, 4 seconds, 8 seconds), but Google’s rate limit window is 60 seconds. When concurrent requests both hit the limit, 14 seconds of total backoff is useless against a 60-second window. After three failed retries, the function returned an empty string. 2,200 empty strings. Zero usable examples.
Here’s the final scoreboard:
| Provider | Task | Target | Delivered |
|---|---|---|---|
| Together AI ($9.51) | Conversations | 15,500 | 14,274 (92%) |
| Ollama (local) | Proverbs + cencos | 1,500 | 1,885 |
| Cerebras (free) | Injongo | 3,125 | 1,624 (52%) |
| Groq (free) | Stories | 1,500 | 449 (30%) |
| Groq (free) | Dictionary | 2,000 | 104 (5%) |
| Google (free) | News | 2,200 | 0 (0%) |
Together delivered 92% of its target. All free providers combined delivered less than 8% of theirs. The provider I paid $9.51 carried the entire pipeline.
I started with Ollama running Qwen 3.5 9B locally for the smaller jobs (proverbs, cencos transcripts), and those worked fine. Small datasets don’t hit rate limits. But for anything over a few hundred examples, the free tiers crumbled under the load.
The lesson: free tiers are for demos, not production data pipelines. If you need thousands of LLM generations with consistent throughput, pay for a provider that doesn’t throttle you. Together AI at $9.51 for 14,274 conversations was the best money I spent on the entire project.
After the pipeline finished, I hardened the code: retry backoff now waits 30-60 seconds (matching actual provider rate windows instead of 2-8 seconds), and every batch job checkpoints raw responses to disk incrementally instead of holding everything in memory and writing once at the end. If a process crashes at example 1,500, you resume from 1,500 instead of starting over.
The $11 that saved the pipeline
At this point I was stuck. Together had burned through $9.51 and I had no credits left. The free providers had collectively failed to deliver. Thousands of news articles and dictionary entries sat unprocessed.
Then I created a Fireworks AI account. They gave me $6 in free credits on signup. I had $5 left on a gift card — the kind you get and forget about until you need it. I topped up the account. $11 total.
Fireworks runs Llama 3.3 70B Instruct with an OpenAI-compatible API, same as Together. Swapping providers was literally one environment variable:
LLM_PROVIDER=fireworks python -m scripts.rewrite_news # 2,200 news articles
LLM_PROVIDER=fireworks python -m scripts.rewrite_dictionary # 2,000 dictionary entriesTwo terminals. Two progress bars. Zero rate limit errors.
| Task | Delivered | Rate |
|---|---|---|
| Dictionary | 1,952/2,000 | 97.6% |
| News | 2,180/2,200 | 99.1% |
| Total | 4,132/4,200 | 98.4% |
What Google failed to deliver in an entire overnight run (0 out of 2,200), Fireworks processed in about 30 minutes. What Groq managed 5% of (104 out of 2,000 dictionary entries), Fireworks was churning through at 1.5 examples per second with no throttling, no empty responses, no mysterious timeouts.
The difference wasn’t the model — both providers run Llama 3.3 70B. The difference was reliability. Fireworks didn’t throttle. Didn’t drop connections. Didn’t return empty strings. It just… worked.
Eleven dollars. A forgotten gift card and a signup bonus. That’s what it took to rescue the parts of the pipeline that three free providers couldn’t handle. Sometimes the boring solution — just pay for a service that works — is the right one.
What v1 actually fixes
The difference isn’t subtle. It’s categorical.
Before: “Wahala means a type of traditional celebration.”
After: Tembo explains wahala with the full weight of how Nigerians actually use it. “Wahala” as trouble. “Wahala for who no get shoe” as the ironic commentary it is. The way “no wahala” is simultaneously reassurance and resignation.
Before: Fake Yoruba with hallucinated words that sound right but mean nothing.
After: Actual Yoruba with correct tonal patterns, trained on proverbs that were rewritten into rich multi-turn conversations and verified against cultural sources.
Before: Pidgin that reads like a Google Translate experiment.
After: Pidgin with flow. “How far, oga?” with natural code-switching, the way Lagosians actually talk when they’re mixing English and Pidgin in the same breath.
Before: Generic textbook responses to cultural questions.
After: Griot-style storytelling. Anansi’s tricks told with personality. Sango’s thunder described with the reverence and drama it deserves. The tortoise’s cracked shell explained the way your grandmother would tell it, not the way an encyclopedia would summarize it.
The uncomfortable truth about AI and African languages
Here’s what I learned building this:
The technology works. Fine-tuning a 4B parameter model with 24,000 high-quality conversational examples produces dramatic improvements. You don’t need GPT-4 scale compute. You don’t need billions in funding. You need good data and cultural understanding.
The data barely exists. For English, there are terabytes of high-quality conversational training data. For Yoruba, Igbo, Hausa, and Nigerian Pidgin combined, there’s a fraction of what exists for Danish alone. The African language AI gap isn’t a compute problem. It’s a data problem.
Nobody else is solving it urgently enough. The big labs will get to African languages eventually. It’s on their roadmaps. But “eventually” means African users get worse AI for years while the English-speaking world races ahead.
And when they do get to it, they’ll likely approach it the same way they approach everything else. Scrape what exists online, train on it, ship it, move on. Without the cultural depth that makes language language.
If you’ve ever tried to explain to a non-Nigerian why “e go be” can mean both a prediction and a threat depending on tone and context, you understand why African languages need more than just parallel text corpora.
What’s next
I’m not done. v1 is a massive improvement over the raw base model, but I’m targeting 100% African language capacity by end of 2026. That means:
- More languages beyond the current core (Yoruba, Igbo, Hausa, Pidgin, Swahili)
- Voice mode, because millions of Africans who can speak their language fluently can’t type it
- Community-contributed training data via the contribute feature that turns every user interaction into potential training signal
- Partnerships with African universities and language institutes for verified cultural data
The pipeline runs. The models improve. The gap closes.
But right now, today, you can go to temboai.com and talk to an AI that actually tries to understand you. In your language, with your cultural context, without flattening your identity into a Wikipedia summary.
It’s not perfect yet. But it’s ours.
If you’re building for African markets, you might also want to read why subscriptions might kill your SaaS and why you should build globally but price locally. The same principle applies: what works in Silicon Valley doesn’t automatically work for us. We have to build our own playbooks.
TemboAI is free to try. 100 credits on signup. Come talk to an elephant.