The Conspiracy of Single-Page Applications, Part 2: State Management Libraries

State management libraries did not become popular because frontend developers suddenly developed a taste for ceremony. They became popular because single-page app architecture turned the browser into a second application that now had to coordinate with the server’s version of reality.
Once that happens, ordinary interface bugs stop being ordinary. They become synchronization bugs.
You type three paragraphs into a field, and a background refresh quietly wipes out your work. You open a modal, then something else closes it for reasons nobody can explain. The dropdown says one thing, the API says another, and a third layer is trying to reconcile both of them. You fix a bug in one place and another one appears because the app now has two copies of reality and neither one is clearly in charge.
At that point the temptation is obvious.
Reach for a bigger state library. Centralize more aggressively. Add more caching. Add more invalidation rules. Add more conventions for the other conventions.
Sometimes that is correct. A lot of the time it is not.
A lot of the time the problem is not that you picked the wrong client store. The problem is that the architecture duplicated truth in the first place.
That is the second conspiracy of SPA culture. It made accidental distributed systems feel like normal frontend work.
State libraries got popular because the client was forced to impersonate the server
In the first essay in this series, I argued that the SPA era turned ordinary application concerns into specialized categories and markets. State management libraries are one of the clearest examples.
There is a short history hidden inside that rise.
Flux’s original documentation explains that Facebook moved toward unidirectional data flow because large MVC-style client applications kept producing cascading updates and unpredictable results.
Redux’s motivation page describes the next stage of the same pressure more broadly: SPAs were now expected to manage cached server responses, locally created but unsaved data, active routes, selected tabs, spinners, pagination controls, optimistic updates, and route transitions.
TanStack Query’s overview represents a later refinement of the problem: once teams realized a large share of the pain was really about remote data, a separate class of tools emerged to fetch, cache, synchronize, and update server state.
That arc matters. It shows these libraries did not become popular because developers randomly fell in love with ceremony. They became popular because teams were trying to manage a real burden.
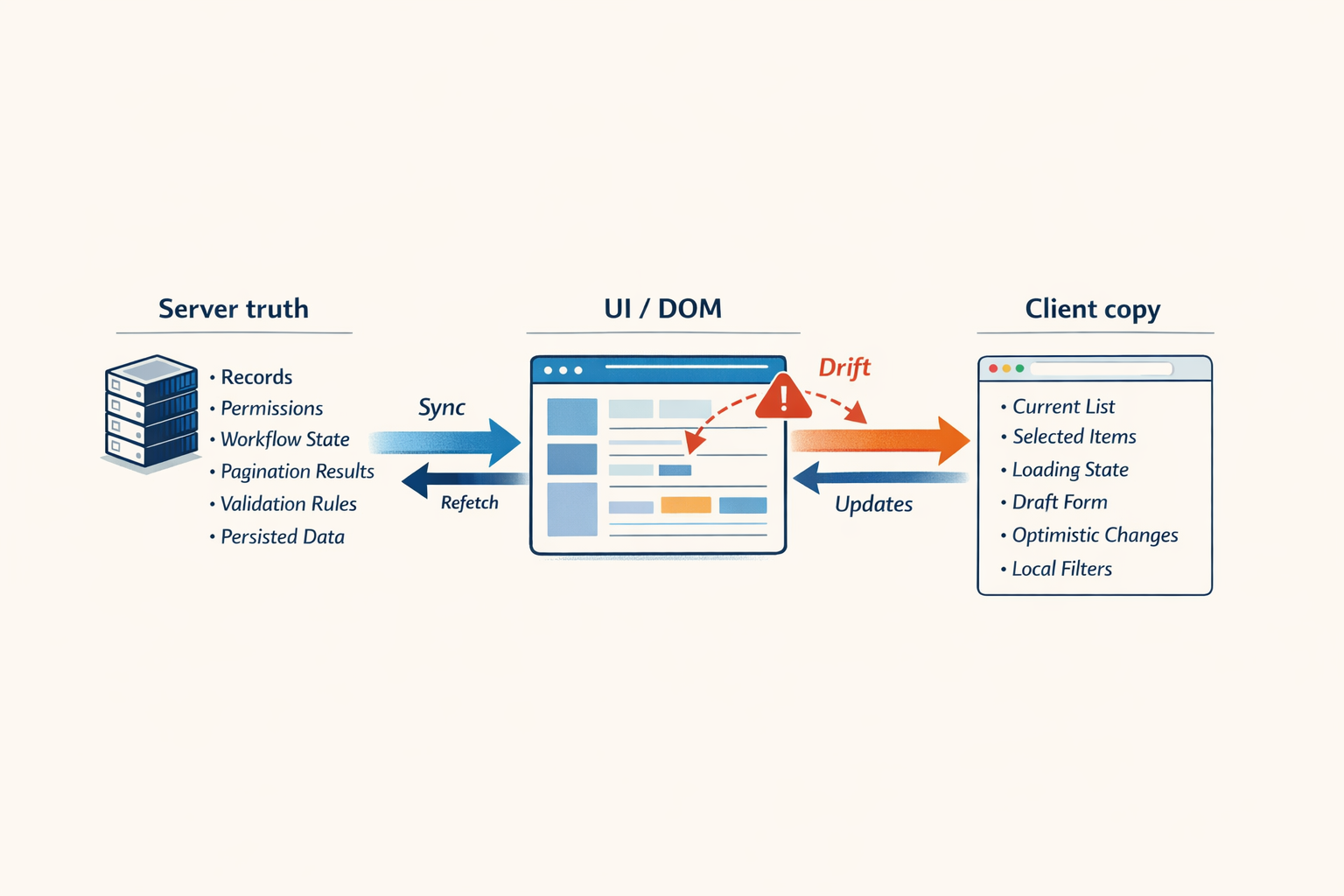
Once the SPA model made the browser carry more and more application truth, it became responsible for coordinating with a server that still also owned important truth.
Now your client has:
- a copy of the current list
- a copy of the user’s permissions
- a copy of loading status
- a copy of selected items
- a copy of draft form data
- a copy of optimistic updates
- a copy of pagination and filters
- a copy of whatever the server might re-send in a moment
That is not just local state. That is synchronization work.
This is why the pain gets so strange. The bugs are no longer just local bugs. They become coordination bugs. The browser believes one story. The server believes another. The DOM is temporarily showing a third. And every new fix is trying to keep these realities aligned without a clear answer to which one is authoritative.
That is not ordinary application simplicity. It is sync-engine work.
The first thing to fix is your vocabulary
A lot of bad state discussions happen because people say “state” as if it were one thing. It is not.
Even the official docs of the tools in question point in a more careful direction.
React’s docs remind you that state belongs to specific places in the UI tree.
Redux’s FAQ is blunt that you do not need to put all your state in Redux and that local component state is often fine.
TanStack Query’s own overview states this directly: server state is different from client state, and treating the two as the same thing creates a long list of coordination problems.
So let us stop speaking lazily. The real fix is not “put your state in the database,” and it is not “put your state in Redux.” The real fix is learning what kind of state you have and which layer should own it.
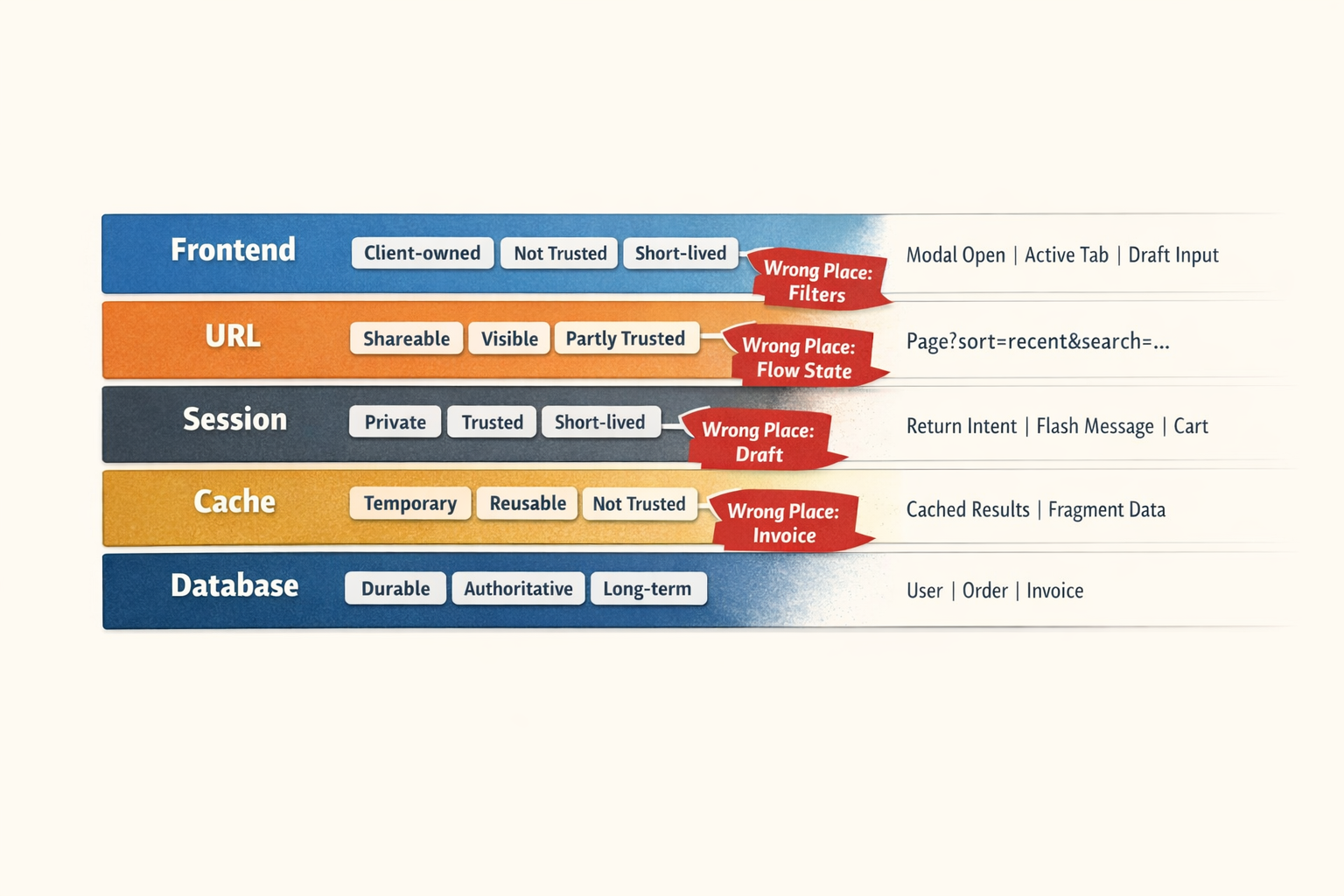
Where State Lives
Most application complexity becomes easier to reason about once you stop asking, “Where can I store this?” and start asking, “What kind of memory is this?”
That question produces a more useful map:
| Layer | Use | Shared? | Trusted? | Lifespan |
|---|---|---|---|---|
| Frontend state | current interaction | No | No | seconds-minutes |
| Query params | URL state | Yes | Validated | while URL matters |
| Session | journey context | Usually no | Yes | one flow/visit |
| Cache | reusable speed | Not the point | No | temporary |
| Database | business truth | Indirectly | Yes | long-term |
If you prefer a shorter version:
- frontend state is for interaction
- query params are for addressable state
- session is for short-term server memory
- cache is for speed
- database is for truth with consequences
That is the taxonomy. The diagram below is the faster visual version. The table is the reference version.
Ephemeral frontend state belongs near the UI
Some state really is local UI behavior.
Is the modal open. Which tab is selected. What is in the draft input right now. Which row is highlighted. What is the current drag position. Which menu is expanded.
This is the sort of state React, Vue, Svelte, Alpine, or even plain JavaScript should own directly. It is close to the interaction, it changes quickly, and it usually does not deserve a global doctrine.
This is one reason Redux’s FAQ says most form state does not need Redux, and why lightweight tools like Alpine or petite-vue still make sense. Not every interaction deserves a central store.
localStorage is worth naming here too, because people often treat it like a separate architectural category. It usually is not. It is a browser-side persistence mechanism for client-owned state. That makes it useful for things like preferences, dismissed prompts, or recoverable drafts, but it does not become trusted server state or durable business truth just because it survives a refresh.
The client is especially well suited for state where timing matters too much for a round trip:
- hover state
- text selection
- caret position
- drag and resize feedback
- keystroke-level interactions
That is legitimately client-owned state. But it does not follow that the client should also become the canonical owner of invoices, permissions, workflow status, or inventory.
Query params are for state the URL should be able to explain
The browser already has a built-in place for state that should be visible, refresh-safe, and shareable: the URL.
MDN’s URLSearchParams docs describe it plainly: query strings exist to work with parameters in a URL.
That sounds obvious, but teams ignore it all the time.
If I should be able to copy a link and send it to you, and you should see the same slice of the application, query params are usually the right answer.
Examples:
- search term
- current page
- selected filters
- sort order
- view mode
- date range
This is the right home for state that deserves an address.
It is not the right home for everything. Private workflow context, anti-abuse flags, flash messages, or large flow metadata generally do not belong in the URL. But when the state is meant to be linkable and legible, the URL should usually win.
Session state is the category SPA culture keeps forgetting
This is the missing category in a lot of modern state debates.
People talk about sessions as though they are only about authentication. That is too narrow.
If you want the identity side of this split in full, Part 1 on auth-as-a-service and JWT covers why the SPA era made ordinary session auth look old-fashioned. The point here is broader: sessions are not just about identity. They are also a way for the server to keep short-lived memory for a browser journey.
MDN’s session management guide starts from a simple premise: HTTP is stateless, so if a server wants continuity across requests, it needs a session mechanism.
Django’s session documentation is even clearer: sessions let you store arbitrary data on a per-visitor basis, and Django explicitly supports anonymous sessions.
OWASP’s guidance describes session management as a process that maintains state for a user across requests both before and after authentication.
That matters.
A session is not just “who is this user?” It is also “what should this browser journey remember for a little while?”
Auth is the most famous use case. It is not the only one.
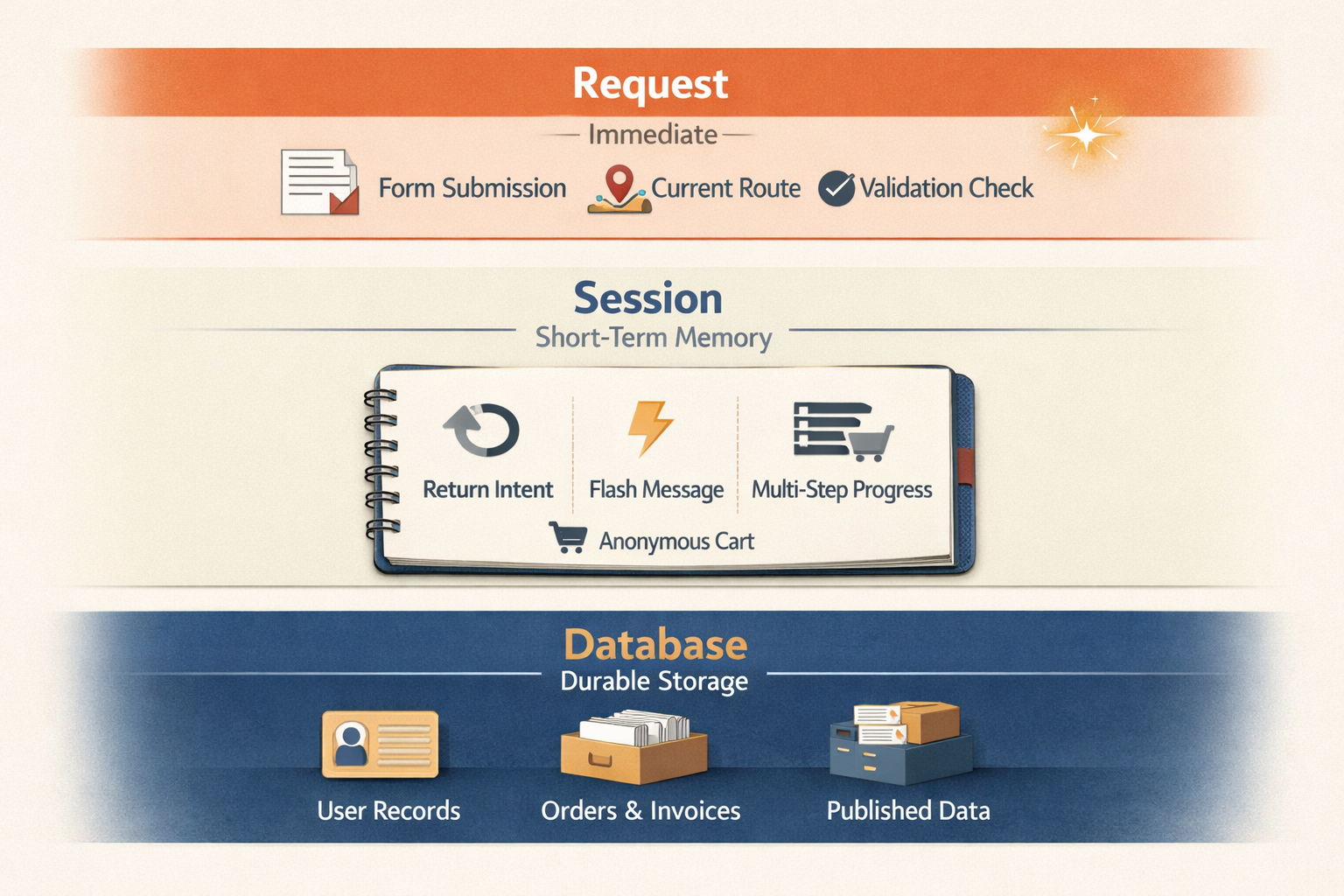
The clean mental model is this:
- request = what is happening right now
- session = short-term memory for this browser journey
- database = long-term memory the business cannot lose
Request is not a storage layer like the others. It is the current scope in which those other layers may be read or written.
Once you see that, a lot of design decisions become easier.
Sessions are useful long before login
The most underappreciated thing about sessions is that they are useful even when nobody is authenticated yet.
A visitor can begin in an anonymous session, move through a flow, and only later attach an account to that flow. That is normal. In fact, OWASP recommends regenerating the session identifier when privilege changes, such as at login, precisely because a session often exists before authentication and then continues afterward.
That is why the “sessions are only for logged-in users” mental model does not hold up.
Where sessions genuinely shine
Sessions are often the cleanest answer when you need short-lived, server-trusted memory across requests.
Good examples:
- complex return context after a detour to login, payment, or email verification
- multi-step forms for unauthenticated visitors
- flash messages that should survive one redirect
- anonymous carts and pre-login checkout context
- locale, onboarding mode, or campaign context for the current visit
- cooldowns, retry state, or anti-abuse flags in anonymous flows
One of my favorite examples is complex return context.
If all you need is ?returnTo=/dashboard, the query string may be enough.
But many real flows are not that small.
You may need to preserve:
- path
- filters
- sort order
- pagination
- active tab
- where the user started the flow
You can stuff all of that into public URL parameters if you want. Sometimes that is correct. But if the return context is private, temporary, or structurally awkward, storing it in session is often cleaner. The session can hold the journey context while the browser goes through the detour, and the server can restore it afterward without turning the URL into a transport format for everything.
That is a legitimate use of sessions. It is exactly the sort of continuity they are good at.
Sessions often beat frontend state for flow continuity
This is where the distinction becomes important.
Frontend state is excellent for what the user is doing on the current screen. Session state is often better for what the system should remember across requests.
There is an entire class of problems where sessions outperform frontend stores:
- redirects
- OAuth flows
- payment callbacks
- login and return
- email verification links
- pre-auth to post-auth handoff
- multi-step flows that should not be persisted yet
Frontend state gets fragile the moment the browser leaves the current page, reloads, or moves through a server-driven detour. Session state is designed for exactly that sort of continuity.
There is also a trust boundary here.
If the state affects pricing, eligibility, permissions, workflow validation, rate limits, or return safety, then treating it as purely frontend state is a poor fit. The client can display it, but the server should be the one that remembers and validates it.
This becomes even more relevant when people reach for localStorage as a universal answer.
MDN recommends cookies over local storage for session identifiers, partly because HttpOnly cookies can keep the identifier out of JavaScript.
That is not a reason to put everything in a session, but it is a useful reminder that not all browser-held state has the same security properties.
The practical distinction is simple:
- frontend state is for experience
- session state is for continuity and trust
Cache is for speed, not truth
Cache is another category people regularly confuse with source-of-truth storage.
MDN’s HTTP caching guide defines the core idea simply: a cache stores a response and reuses it for later requests. That is a performance mechanism. It is not a canonical record.
Use cache for things like:
- expensive query results
- rendered fragments
- dashboard aggregates
- upstream API responses
- data you can recompute or refetch
The right question for cache is not “Should we remember this?” It is “Would it be helpful to avoid recomputing or refetching this right now?”
That sounds similar, but it is not the same thing.
The difference matters because caches can be stale, evicted, or rebuilt. That is acceptable when the cache is a performance layer. It is a disaster when the cache has quietly become your only record of something that matters.
This is also why personalized pages need careful cache behavior.
MDN’s caching guide explicitly notes that personalized content should generally be marked private, and that no-cache or no-store have different meanings.
If your response depends on cookies or session context, that fact should shape the cache policy.
Cache is memory for speed. It is not memory for truth.
The database is for durable business truth
The database is where things go when losing them would create real business pain.
Users. Orders. Invoices. Subscriptions. Permissions that must persist. Published content. Workflow states the business needs to audit tomorrow.
This is the state the business cannot casually forget.
That is the main distinction. If losing a piece of state would create customer pain, financial pain, operational pain, or compliance pain, it probably belongs in durable storage.
This is why it is usually a mistake to swing from “too much client state” to “put everything in the database.”
A modal being open does not belong in the database. A flash message does not belong in the database. A one-off return context does not belong in the database. A step index for an anonymous application flow often does not belong there either.
The database is not a dump for every transient fact in the system. It is where durable business truth lives.
A better rule: choose the right home for the state
A large share of application complexity is simply state stored in the wrong layer.
Examples:
- business truth forced into frontend state
- private journey state forced into query params
- temporary flow state persisted too early in the database
- cache treated as if it were a canonical record
- session used as a catch-all store for data that should have been modeled properly
That is what makes systems feel heavier than they need to be.
The better rule of thumb is to ask five questions:
- Should this survive a refresh?
- Should this be shareable as a link?
- Should the server own and trust it temporarily?
- Can it be recomputed or refetched if lost?
- Would losing it be a business problem tomorrow?
Those questions usually point to the right home:
- if it is purely immediate interaction, keep it in the UI
- if it deserves a link, put it in the URL
- if it needs short-lived trusted continuity, use the session
- if it is a reusable copy for performance, cache it
- if it is durable business truth, persist it in the database
This is why the modern monolith feels calmer
This is one reason I keep coming back to Inertia and The Boring JavaScript Stack, and more broadly to server-led web applications. Inertia’s pitch is explicit: keep routing, controllers, middleware, auth, and data fetching on the backend, and let the frontend focus on rendering and interaction.
That architecture does not eliminate client state. It gives it better boundaries.
The server can own page data, validation, authorization, sessions, and redirects. The URL can own shareable filters and view state. The client can own local interaction and draft behavior. If you need cache, you add cache. If you need a global client store, you add one for truly client-owned shared state instead of as a reflex.
Inertia’s validation flow, partial reloads, and remembered local state all point in this direction. So do Hotwire, Phoenix LiveView, Laravel Livewire, and Datastar. Different mechanics, same underlying instinct: keep browser concerns in the browser, keep server concerns on the server, and stop duplicating authority without a good reason.
That does not make state libraries obsolete. TanStack Query exists for a reason, and its own docs are honest about why: server state is genuinely difficult once you decide the client will coordinate it directly. The mistake is not using the tool. The mistake is treating that architecture as the natural default for every dashboard, form flow, CRUD app, and back office.
Where frontend state libraries still fit
Frontend state libraries still have a real place.
If you are dealing with truly shared client-owned state across many parts of the interface, a central store can simplify the system instead of complicating it. If you are building an offline-first tool, a collaborative editor, a whiteboard, a design surface, or a product that behaves more like a native application than a page-first web app, stronger client state management is often justified.
The same applies when the browser is not just rendering a server-owned page, but genuinely hosting a large, fast-moving interaction model of its own. In that kind of product, the client is not merely mirroring truth. It is actively producing and coordinating truth in real time.
That is the boundary that matters. Use a frontend state library when the client is the rightful owner of the complexity. Do not use one by reflex when the browser is only struggling because the architecture duplicated server truth and now needs help managing the drift.
The real rule of thumb
Stop asking, “Which frontend state library should we adopt?” Start asking, “What kind of state is this, and who should actually own it?”
If it is UI interaction, keep it close to the UI. If it belongs in the URL, let the URL own it. If it is short-lived server memory for a browser journey, use the session. If it only exists to make repeated work cheaper, cache it. If it is durable business truth, persist it in the database.
That is the deeper point.
The real problem was never “state management” in the abstract. It was treating every kind of state as though it needed the same home.